DNA culture
Continuously learning and evolving
Creating great products that will impact every person in the world
is an immense task.
Succeeding requires a culture of professionalism, consistency, learning
and rapid change.
We imitate this culture from nature -- we define our DNA,
and we change it as we learn new and better things. Our DNA is our shared
memory for how to do things right.
Be consistent
The DNA is our shared memory of how to do things right, so work according to that DNA. If you find a way to improve on our DNA, share that with dna@hola-org.com and influence change in our DNA.
- with yourself
- with your peers
- with existing work methods
- with existing codebase
- with the industry, if no Hola internal method exists
Code style
We are highly pedantic in keeping our codebase perfectly consistent with our coding conventions. When none exist, or the specific case is not covered, we use the existing current codebase style as a guide.
Email style
Email consistency, just like source code consistency, helps handle large
amounts of email efficiently in our team.
That's why we keep our email styling consistent with our
email style guide, and look out for unwritten
conventions in the way Veterans communicate in
the company, and follow their style.
Create procedures
When we do something new, or something un-documented, we improve our consistency by creating a procedure. This documents the task we are doing, to ensure better consistency next time this task is carried out.
Learn
When we do a task which is not standardized, we find out how it was done previously by others. We also provide you with general knowledge you need to have while doing specific roles in Hola. If more information is needed, ask Google.
Learn from unwritten de facto standards
If you are doing a task which is not standardized, look how it was done
before.
Not all aspects of tasks you do have a written standard or procedure. So how
do you learn how to do them? By seeing how it was done previously
by others, and learning from them.
Learn by imitation
Imitation is a very powerful learning tool. Look at the highly productive
veterans in the company, and try to imitate
their working habits, large and small.
If you choose to imitate the veterans who better fit your character and style
of work, you will quickly improve your efficiency and productivity.
Teach
Be an enthusiastic agent of the DNA - spread the word, refer to it in your communication, ensure that your daily activities are in line with our DNA, teach others about the DNA, and help new employees get to know the DNA.
Kill obsolete features
Old features keep us behind. They prevent us from moving fast into the
future.
If you see procedures that are no longer needed, features in the
product that are no longer in use, or no longer bring us value, obsolete
documents etc. - remove them! Removing obsolete procedures/code/features
greatly simplifies our product and daily work, makes it easier to change
things going forward, makes us leaner and more efficient!
At Hola, we try to get rid of outdated and unused stuff, be it big modules
and services that no longer add value or small pieces of code.
We go the extra mile to remove code/modules/features that are obsolete and
no longer in use, as well as 'future use' code that was never used.
If 'future use' code is still unused, with no signs of anyone working on it
for the past two weeks, why is it still there? We either
release it or remove it from our source code. We
don't accumulate things that may be useful someday; either use them
now or forget about them.
Our users come first
Our users and customers are the reason for our existence. We try to
constantly understand their needs, find out their pain points and solve them.
We constantly evolve, improving our services, features, and products - we do
everything we can to bring them significant value as they are our most
valuable asset.
Why it is essential to put customers first
Mindfulness: think before you act
We strive to be unswervingly self-aware, which facilitates being intentional
about how we act, what we do, and how to constantly improve.
Our behavior and actions should have a cause. A reason. Well-thought from
beginning on the full flow and the end result.
Having a well thought-of reason in advance helps us make our actions more
consistent, and if the action is later found out to be incorrect, allows us
to find the root-cause in the mistaken reasoning that was used and improve
the reasoning for in future actions.
Mindless actions do not allow improvement in the future, because they were
not derived from a systematic well-thought of reasoning:
if they had a positive outcome - we cannot repeat them, if they had
a negative outcome - we cannot avoid them repeating.
Even hacks should be well thought of
Even hacks should be well thought of in advance. Especially hacks!
Hacks are a very powerful tool of quickly solving real problems, and
implementing real features with great value, in a short time. But in
return, they require you to think it out well through in advance, to make
sure the hack is worthwhile, and is not going to cause more damage
than its value.
We are a professional team
We're a team - like a pro sports team, not a kid's recreational team. Hola hires and develops smartly, so we have stars in every position.
Who we recruit to join the team
We look for people who share similar values to ours: They are pros,
ambitious, they love to get stuff done,
love to learn and love
working with similar such people.
They are also smart, and
masters of their domain.
Having these types of 'stars' in every position makes it a pleasure
to work together.
We typically need to interview 250 people to find someone like you.
Congrats!
However, any interview process is limited and cannot be fully predictive.
We hire a candidate that shows traits of being a star.
If we are not 100% sure that they are a perfect DNA fit,
we let that person know of our concerns, and we go ahead and hire for
the bootcamp
to give that person a chance to learn the company DNA and
become a productive member of the team.
The first weeks of our work together serve as a mutual get to know period.
At your first 3 weeks at Hola you are a temp employee for a period of
mutual 'get to know', with the intention of making the transition into a full
hire during that time.
We rarely let people go after the initial temp period, because by then
the person has shown great capabilities and ability to let them flourish
at Hola through the DNA. We don't believe in 'cutting the
bottom 10%' or similar concepts.
Our best new employees were those who made an effort to learn and implement
the "Hola way", on their own and with the assistance of their mentors.
They later also had a great influence in improving and evolving our DNA.
Joining the team - Bootcamp
Congratulations on being selected to join the team!
Professionals like you are rare, and are what excites the rest of the
team here. We are looking forward to you becoming an integral part of
our professional team.
The 3 week Hola bootcamp
is your first step from candidate to
Hola Noob,
where your mentor will guide you to success.
You will learn the workflows, start with simple tasks and move up to mini
projects.
Initially you will receive tasks that don't require background knowledge of
our products, allowing you to focus on the workflows, make your first commit
in the first day, and start contributing from day one!
Your first day at work will include developing a small feature and
releasing it to millions of Hola users!
The tasks will get deeper into our technology as you advance.
We will provide you with a list of things to review prior to bootcamp,
including: information about the company,
products,
DNA, coding conventions,
basic tools and methods of work, and access to your mentor for any
questions you may have in advance.
Becoming a team veteran
Congratulations on successfully completing the bootcamp! You are now on your journey from Hola Noob to Hola Veteran. The goal of this process is for you to evolve from someone who can be part of the pro team, to someone who is an integral part of the team. Here's the process you'll be going through:
- Hola Noob (first 3 months): During this period, you will be assigned larger tasks, that will allow you to make a significant contribution while actively learning about the company's DNA, software architectures, and work methods. You will still have code reviews for most of your commits, while in some cases you will be approved to commit without a pre-commit review session - your code will only be reviewed after the commit, and sometimes even only after deployment.
- Hola Junior (first 1 to 2 years): Now you are becoming a major contributor to Hola's products, developing specific domain knowledge in fields that are of interest to you within Hola. You may commit directly to the product tree without prior review, and you will see your contributions going live to millions of users within hours of being developed. At this phase you are still internalizing Hola's DNA and best practices, and will need to be open to comments about your commits from other Hola Veterans.
- Hola Veteran (after 1 to 2 years): Congratulations! You are now a Hola Veteran - an integral part of the Hola Family. You are a major contributor, a knowledge center, and a person who can help Noobs and Juniors get up to speed on the Hola DNA and best practices through mentoring, and code reviews. You've made a long way!
Hola Veterans are the core of the team. You will make immense contributions
to our products, our business and our values.
We will make your work environment the best it can be, we will care for your
work/life balance, your compensation, your happiness and your career,
allowing you to move between tech groups to work on things you care about. We
will do everything we can to make Hola the best place for you.
If you choose in the future to check out other opportunities outside of Hola,
we will always welcome you back as we've done in the past.
Hola developer Veterans are typically not let go from Hola.
Transparent
We communicate
openly,
clearly,
truthfully
and with
precision
Open knowledge facilitates free information exchange, allowing us to learn
from each other and make smarter decisions.
We share all information within our team, as well
as in our ecosystem (customers, partners, market)
- unless there is a compelling reason not to.
All open, no secrets
Except for compensation packages, all work-related information is open to everyone at Hola; from source codes and working hours, to project status and reports, and future plans.
Avoid BCC in emails
Try to avoid adding BCC (blind copy) recipients - it is usually a sign of non-transparency.
No black-boxes: Share all info!
We each provide clear information on areas of responsibility and expertise, our current tasks and activities. We do so, to allow anyone to get the full 'raw data' and to be able to question our decisions and actions in our area.
A: Helped customer integration.
A: Helped customer 'greatprice.com' integrate python code snippet version 2.7.5. It took around 3 hours.
A: Sorry, my mistake. Won't do it again.
A: I deployed code that caused DB to be 30% slower, making the site to go down.
I reverted it already, and now it is all OK.
Site downtime during this was 2 minutes.
To prevent this happening in the future, I added metrics and alerts on DB response times. I also added a unit-test to validate DB performance, and in the future I will also test in small scale DB schema changes that may cause performance problems.
A: Sure. I have the list on my laptop, I can show you.
A: Sure. The file is located in our shared IT folder. I'll send you the direct link. Around 65% were already upgraded.
A: It complex to implement, and will bring little value.
A: It's complex to implement: I estimate it will take me around 2 weeks, because the tracking DB module will need adjustments. On the other hand, I think it will bring little value: I estimate its response rate will be 2% or less - which is not significant.
Privacy
Information is open to everyone at Hola. This transparency is provided to allow you to get your work done without requiring permissions, which slow you down. However, accessing information which is not directly required for your work is forbidden. Also, to protect our user's privacy and our trade secrets, it is absolutely forbidden to share internal Hola information with anyone outside of Hola. Any such sharing of internal information will lead to immediate termination and additional consequences.
Communication should focus on clarity, not politeness
It's important for us to communicate clearly, delivering direct feedback. Critiques allow for self-improvement. Political correctness prohibits conveying messages successfully.
Feedback
We provide direct feedback. People who are not accustomed to it, may consider it blunt and possibly even hurtful. Remember that this is not a reflection on your abilities but on the specific result, and that the goal of this feedback is to allow you to learn. When Steve Jobs was asked about his sometimes "harsh" feedback, this was his response:
So we provide feedback about the work itself, not about the person doing it.
We do not use cynicism or sarcasm in our communication. We do talk about the problem directly, with clear facts.
Be precise, clear, and specific
Be exact in your communication; avoid vagueness and jargon. If you are too generic, you leave too much space to ambiguity; specific communication ensures messages are conveyed correctly and expectations are met. High level terminology or jargon, moreover, are often used as an excuse not to make an all-out effort for handling a difficult issue.
Specific
We communicate precisely, with specific details:
Easier for the writer
Easier for the readers
It's a review of the video streaming market, showing that P2P tech is taking off in APAC. Consider if and when this gets added to our offering.
- Save reader's time (Mindful of coworker's time) - provide a summary: It's a review of the video streaming market
- Point readers to what's interesting in the article: showing that P2P tech is taking off in APAC
- Specify actions (Action-oriented) you want them to take: Consider if and when this gets added to our offering
Another vice to look out for is high-level terminology. Sometimes high-level terms are only used as an excuse for not making an all-out effort to handle a difficult issue:
while we prefer a more specific wording; in this case:
At Hola we make a special effort to always be specific when we communicate. Here's an example of an email that we may want to send, and how we can improve it:
At Hola, the email we would send would be:
This email is more precise and specific, resulting in better communication.
Accurate
Explain your idea accurately and get to the point; your messages should be supported by good reasoning.
Provide data, facts and specific use-cases
In God We Trust. All others bring Data
The decisions we make are based on real world data.
When communicating, the use of data helps our peers understand the exact
issues you are trying to solve,
and why we are trying to solve it.
We focus on real issues, not on theoretical problems or rare use-cases.
This principle is called
Genchi
Genbutsu ("go and see") in Toyota Production System.
We try to make mindful rational decisions,
based on real world data, facts and use cases.
- "Better design": With such a statement you need concrete facts on why is the design better, what exactly does it solve, is what it solves really important enough to be solved, how much value will it bring, how much work and effort is required to implement this design change...
- "Very dangerous code": Will it really cause a bug? How often? And if it does cause a bug - will the bug not be detected and fixed very quickly? How severe would the theoretical damage of such a bug be?
- "But what if the user clicked here, and then here?": Give a use case on how and why this could happen. Is it really common for the users to do this? And if they did, how bad would the negative impact be?
Providing concrete data will give your colleagues a firm basis for either agreeing or disagreeing with your idea. This scientific scrutiny approach improves the quality and assurance in your ideas and suggestions, once they passed the healthy questioning.
Think - don't brainstorm
Think deeply about the subject, form a viewpoint, and present it as an actionable plan. This process leads to concrete action. Brainstorming is the opposite of constructive thinking.
Dispute if you don't agree; yet focus on getting things done
Stand up for your beliefs: dispute tasks that you
believe are wrong or can be improved, even if its from the CEO!
But, this should not come at the expense of
getting things done (GTD).
How to dispute while staying productive:
- Give your negative feedback immediately
- Before you express your objection, think deeply - to make sure your objection has sound reasoning.
- Be specific and accurate in your reasoning.
- Try to in the meantime implement what you partially agree upon, or something minimal that will partially please the requestor, and complete it once the dispute is cleared.
- If the requestor did not agree with your reasoning - then do as requested.
Immediate
We do things immediately, so that we can evolve and improve faster
A startup's engine for creating better products is a constant
Learn-Build-Measure loop.
It's unlikely to succeed on the first try; so we iterate on the product
until it's fit.
The more responsive we are, the faster our products will
evolve and improve.
Do small tasks immediately
We do quick tasks immediately, even when they're not particularly important, to avoid the overhead of prioritizing and of reopening their context.
Do small tasks yourself - don't delegate
Quick tasks are not worth delegating. The communication and management involved in the delegation process take more effort than the task itself. If you have received a small task that does not require any technical skills (for example, typo corrections), help the sender learn how to fix it himself.
Decide fast
We discard promptly new ideas that appear to be flawed, and adopt brilliant ideas as soon as possible. If a new idea presents multiple pros and cons, and we don't find it brilliant after a short discussion, we put it on hold or discard it.
Manage your inbox
Email responsiveness and never losing an email (forgetting to respond) is critical for efficient and reliable email communication with our peers. So we strictly follow the email handling guidelines, that include rules such as:
- Respond quickly to email - handle email in LIFO order
- Clean out your inbox constantly - never end your day with more than 10 emails in your inbox
- Move emails out of inbox (to Archive/Trash) after handling - "Read" status should not be used as an indicator for handled emails.
Prioritizing incoming tasks
What's a small task and what's not?
When to act immediately and when to postpone?
The timetable below can help you determine your actions according to the task
you are handling:
| Time to complete | What to do? |
| Up to 10 min. | Do it immediately, to avoid the overhead of postponing and reopening the task later and respond to the requester. |
| 10-60 min. |
If possible, try to give immediate partial solution/responses. Log it in your version plan and respond to the requester that it will be done within the next 1-3 days. Notify the requester as soon as you complete the task, or if it gets delayed again. |
| More than 60 min. |
If possible, try to give immediate partial solution/responses. Log it in your version plan and update the requester on when you plan to implement it. Mark it in your calendar, and update again the requester if you decide to delay once more. |
It's OK to change a schedule if other tasks come up or take longer than expected, but we update the requester with the new schedule.
Immediate Answers
Discussions with questions left unanswered lead to other discussions. To end discussions with results, all questions should be answered, even if the answer is an estimation. Estimations allow us to proceed with the discussion and take action. The actions can be adjusted later with the accurate answers.
A: Let me check and get back to you.
A: About 1K.
Provide ETA
When asked to do a task, provide the requester with an ETA. This helps
the requester plan his other activities.
If you see you will not be able to meet the original ETA,
it's OK to change it, but update the
requester with a new ETA as soon as you know you will miss the original one.
A: Will do.
A: Will do, ETA for 1st draft end of day tommorrow.
Incremental and evolutionary
We split large tasks into small tasks that give immediate value, so that
we can make quick incremental improvements
We've learned the hard way that you do not know how a product works for
customers, until they've been using it. The biggest waste of our time has
been when we put major efforts on a tangent, only to find the whole
direction was wrong for a reason we could have detected earlier. We learned
that you should release very early, and make incremental improvements.
Minimal Viable Product (MVP)
When you work on a product, feature, document, graphic design or any form of delivery (even a bug fix!), one of the most creative and important parts of the design are to design the smallest conceivable delivery, that brings some initial value. Design it, release it quickly (hours?) and then iterate on improving it.
Rapid experimentation
Fast evolution requires rapid experimentation.
We love experimenting with new ideas/features/technologies/solutions.
We measure the experiment worthiness by the cost (building it,
deploying it, cost of failure) and by the expected outcome.
If the cost is too high, or the best expected outcome too low,
the experiment is probably not worth doing.
We love cheap experiments that can lead to high outcomes.
Fast feedback loop
Fast feedback loop reduces the time it takes to build a feature as originally intended, by getting the feedback on a wrong direction early on, before completing the whole feature.
- Split up the feature into as many committable subtasks as you can, so that each subtask gets its own incremental feedback early.
- Done some initial UI? Even if the feature is not working, send a screenshot or animated GIF to demonstrate how it will look, to get early UI feedback.
- Basically working? Even if the feature is only partially working, call in the requestor to play around with it (or remotely via screenshare).
- Completed (deployed)? Send the requestor a link to the feature, and a diff URL to show what has been done.
All examples cited above minimize iteration time and bring value almost immediately.
DONE is better than PERFECT
"A good plan violently executed now is better than a perfect plan
executed next week"
George S. Patton
Getting things DONE has a very high value. It solves the problem, and allows
learning which additional improvement iterations are required.
PERFECT is the biggest single enemy of DONE: trying to do a task perfectly
will in most cases prevent us from completing it.
Sign
at Facebook

{kind=link}
Pragmatic Craftsmanship
We take pride in our work, and invest time to produce a quality outcome. However, we also take pride in continual progress and moving fast, so we make sure not to take craftsmanship too far before shipping.
Move fast and break things
Moving fast ultimately will be why we succeed.
Yes - we break things while moving fast, but we fix it even faster!
Sign
at Facebook

Little better every day
Do only a little better every day, and you are 37x better by the end of the
year.
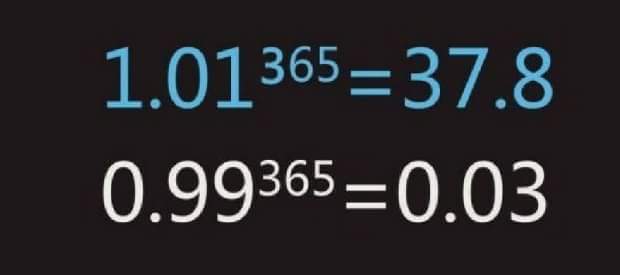
Incremental task handling
When starting a new task, we break it down to smaller tasks that can be
released on their own, and can bring value on their own.
A good size increment is a few hours of work.
An example of that principle is this DNA document itself!
When we understood that we want to formally define our DNA,
a quick doc was written up in a couple of hours, with many naively stated
points, and 'please contribute more here' types of ideas.
That document was uploaded to our website under
http://hola-org.com/dna for everyone to see,
immediately and transparently.
From that point on, many people read and improved, erased, and added to make
this document better with every iteration.
Even today, it is still work in progress...
Give immediate partial results/response/value
Often, a question or call to action may be stuck in your inbox for a long time because you are not sure of the complete answer, and do not have the time to work on the whole 'project'. It's better to give immediate partial results/response/value, and email the full results later. This enables the other party to start with something, and possibly shed light on the rest (for example, the rest might not be needed for the other person to make progress).
Split up large tasks
Split up large tasks into smaller tasks that give immediate value even before
the large task is completed. Example: When developing a large new feature
such as the stats dashboard for the CDN, define a small set that brings value
that you can commit in one day (such as only start time and only for past 24
hours), go live, and improve iteratively from there with more commits every
day.
You cannot complete the task within a day? work is still in progress? No
problem, just do a commit and state it's "Work In Progress" (WIP), so your
code will be added to the codebase and some progress will be made.
Get something small DONE every single day
We make sure every day we personally get some task (big or small) completely
DONE: do a commit, close a deal, solve a real problem...
Even if it looks like a small progress, it will ensure your incremental
contribution.
No branches
At Hola we deliberately avoid branches as a means of improving
transparency.
Branches hurt transparency, because there is no single shared view of all the
info, since lots of info gets hidden into many branches that are not viewable
in a plain simple view. For example: try viewing videojs project in GitHub
with all its 2900+ branches (forks), concurrently. You will not manage.
If all forks were merged into one single top-of-branch best-of-all, all
possible features of videojs & its branches (forks) would be easily available
to all.
Branches contradict two other core DNA values:
incremental and
immediate:
- Immediate: We do continuous deployment, so commits are (nearly) immediately deployed. Branching contradicts it, because the commit is not immediately deployed (only if-and-when the branch is merged). Also, if we have branches, the commit is not immediately deployed.
- Incremental: Instead of having every commit incrementally modify our product, branches make 'bulks' of changes at the time the branch is merged back into the product.
Action-oriented
We choose to solve a problem over stating that one exists. Prefer actions
over words
We can only bring more value to our customers and to each other through
actions. Offering new, well thought-out ideas is great, but must be followed
with an action plan of how you get it done, so that your ideas turn into
products.
Get things done
See David Allen's Getting Things Done (online introduction) system: every commitment should be clarified until it is actionable, any project can only be completed by taking appropriate actions until it is complete, planning is a support tool for getting concrete, physical actions done.
Issues, Problems and Bugs
Problems are everywhere. Anything we see is something that can be improved. Every product has an endless number of bugs and points to improve. Many things need to be changed. Just stating that a problem exists does not bring value -- solving the problem does!
Translate issues solutions
Translate issues/opinions/suggestions/problems into actionable solutions.
is just an actionless opinion. An actionable version of could be
We can have a similar effect by putting an action bar in our home page. I will create a mockup for an MVP, and test it out.
Reality, not theory
We focus only on reality: on real customers, real use cases, problems that actually happened, and our actions are based on these real immediate issues. We avoid future planning, or solving problems that did not yet happen. Our experience showed us that any work we spent on theoretical issues always turned up in the end to be a waste of time. Actions based on future theoretical issues are called at Hola 'over engineering'. By handling only today's problems, we place our trust in evolution to guide us to a successful future.
Research by delivery
Researching and learning in Hola is always carried out by action, by doing, by implementing, by delivery.
- New to nodejs? you will learn it in Hola by actually writing code in nodejs.
- Need to learn how to deliver code contiguously, over 20 versions a day? In bootcamp you will deliver your own code and learn by doing it yourself.
- Want to research on whether to create a new product? Just create an MVP, release it, and learn from the reactions of the customers.
- Researching on right architecture to solve a performance problem? Just experiment by trying out small changes in the existing code, and see how they improve.
We research via real life experimentation, and by incremental steps to see if the direction of our solution is correct. We don't just sit, think, and fill our heads with thoughts for a month. Instead, we implement many small ideas in different directions and see what works and what doesn't. This way, once we solve the problem, it will be a field-tested solution, already implemented and delivered in the real world.
Solve it
If you encounter a problem, do not suggest how to solve it - solve it!
Make sure it is really solved!
You have resolved a problem or finished a task - great work and well done!
However, it is not DONE until you have communicated with your customer
directly, and received his feedback.
Note that it can be an Hola customer or an internal one (one of Hola
employees), for whom the task was done.
Do, don't talk
"When you have to shoot,
shoot - don't talk"
Hola'ers are doers, not talkers.
Actions, not words.
Products don't get created out of talking. They are created out of
coding.
Do yourself
The best work is done alone, or one on one, not in meetings.
The only scheduled meetings we have at Hola are the 'all hands' meetings
every two weeks, and they are limited to 10 minutes after lunch.
Other than that, we don't have meetings.
We believe that while sometimes they may be productive, they are typically
a waste of time for most of the participants,
and above 2 participants ego overcomes logic.
We prefer to do one on one ad-hoc meetings in person or by video,
pulling in an extra person when really needed.
What about situations where multiple stakeholders are required to
completely solve a problem?
We've found that the deepest solutions, which are also usually most
time-efficient, involve only one-on-one meetings.
Here's how: The owner of creating a comprehensive solution creates on his
own what he finds to be the best overall solution.
Then he incrementally iterates
on it with each stakeholder separately,
considering the new feedback received each time to make a better
and better plan.
Avoid meetings
Meetings are the opposite of doing. When you are hosting a meeting with your peers, you are not: writing code, debugging, finding and solving problems, talking to customers... We don't have a meeting room. Avoid meetings - just talk to whoever you need ad-hoc, over lunch etc. And never set recurring meetings.
Convert discussion into action
After discussion summarize to your peer the main points you had, which next actions needs to be taken, and who is responsible for each action. Actions should be recorded in version plan to make sure nothing is forgotten. See GTD.
Actionable communication
Our communication is actionable, and the action is preferably for
ourselves!
We don't just email:
rather we email:
Individual contributor
Those who complete tasks on their own from start to finish create the
largest impact
The people with the largest impact are those who do complete tasks on their
own, from start to finish. Each manager at Hola spends at least 50% of
his/her time on getting real tasks done.
Company as a collective of Peers
Hola is the sum of its employees. Each person brings a real tangible self
contribution to the final product.
Something you can point out proudly to your mother and say "I did that!".
Work Peer to Peer directly
Hola is a P2P company. But not only our products are P2P, so is also our
daily work method: people in the company work directly with their peers.
We do not pass things through "Managers" (a.k.a. "central servers"...),
rather if you want to get something done, you just go directly to the
relevant person who is responsible for that domain.
No managers needed!
Solve yourself, don't create work for others
Each of us solves problems and tasks independently, from start to finish. If you did some work and passed it on, then just the overhead of the context switch within the company probably wasn't worth it. Prefer to do the complete task. If you believe you will not be able to do it from start to end on your own, pass it on in its entirety to someone who can.
Don't pass on subtasks
We avoid passing on subtasks - namely, smaller parts of a bigger task - to others: it's unfair to your peers and the overhead of context switch within the company makes it inefficient:
- Involving another person
- Describing the task again
- Passing on all relevant information
- Explaining the full context of the task
- Validating on completion that it was done as originally intended
No 'half' tasks
When each of us does a task, we do it end-to-end. No 'half-baked' tasks. No 'helper' to clean up after us. Even doing 80% of a task, and passing on to a peer the remaining 20%, will sum up to 200%, double than the original task size:
- You 80%: your original 80% work
- You 20%: preparing a good email to your peer describing the task
- Peer 15%: context switch time, learning the email, the task, understanding what's needed and the background
- Peer 5%: asking you back some clarifications
- You 20%: giving him the clarifications
- Peer 20%: peer's 20% work (what you passed on to him)
- You 20%: checking the task as a whole and seeing it still has a problem
- You+Peer 10%+10%: closing the final issues to get the task perfect
Total sum of 200%, instead of 100% due to the context switch and communications cost. The overhead of incomplete work is much higher that you would expect - that's why we avoid it.
Be mindful of your coworker's time
It's easy to feel like you deserve the time of your coworkers.
For example, when you're trying to improve a certain aspect of the
company, and your coworker can help out with that, it means the whole
company is better off. But every interaction comes with a cost: your
coworker's time.
This fact is dramatically more important in creative and problem solving
fields like computer science, where being in the 'zone' can mean the
difference between a really productive day and a day where every line of code
is a struggle to write.
Getting pulled out of the 'zone' can be jarring, and getting back into that
mental mindset can take a frustratingly long time.
This goes doubly so for companies with remote workers. It's easy to notify a
coworker through chat or text message or IM that you need their help with
something. Maybe a server went down, or you're having a tough problem with a
bug in code you're unfamiliar with. If you're in a global company, time zones
can become a factor too.
Your coworker may be at home with his kids, or otherwise enjoying his
non-work life.
Consider keeping a list of issues you'd like to discuss, and lumping them
into one discussion to respect your colleagues' time.
Before asking colleagues questions, try to find the answer yourself.
You will find that in many cases, reading the source code,
grep,
google and our
Intranet are your friends.
For example: Don't ask a fellow engineer "What is David's mobile number?" -
look it up in the contact list.
Let me google that for you
We avoid asking our peers questions we can ask Google: Let me google that for you
Let me grep that for you
Just like Google is great at answering questions of public info,
grep is an amazing at answering questions about our source code.
The right grep can immediately give great answers.
We made it even easier to grep by our usability wrapper above it:
rgrep!
If you can grep, grep - don't ask!
Writing mindful emails - taking time to save others' time
We optimize emails we write for making them simple to understand and act on for the other side. We take time to write the email carefully and review and modify before sending out, to make sure we are mindful of our co-workers' time.
This email would require all readers to open the article, even if the article does not concern or interest them, and the message's wording does not focus the readers on what is interesting about the article.
Don't have the time to write a great email? Better not to write it at all.
Do no harm
How do we move forward fast? by never going backwards!
When every single peer in the company contributes value every single day,
a lot, or a little, the company as a whole will move forward rapidly.
Avoid degradation
Implementing a new feature? Trying to fix a bug? Modifying code? Improving the installation flow? Suggesting to add a new tool? Whatever you do, just make sure you do not degrade the existing situation.
- Every new version of the product must in the very least not degrade the product.
- Every commit must keep the build tree 'green'.
- Every new tool must not degrade current ease of development.
Wasting peer's time
A great company is combined of individuals who, on the one hand, are super
productive and contributing on their own, and on the other hand do not set
back other colleagues in the course of their own work.
You should bring value to Hola - at the very least, do no harm:
- Losing a customer
- Releasing a bad feature
- Degrading the product
- Wasting other people's time
The last item - wasting your peer's time - is the most significant!
If you commit code that breaks the tree, other developers cannot check out
and commit their own work.
If you code a great feature, but in the process you consumed peer's time by
asking for help, you prevented your peers from progressing in their own
features.
Our peer's time is always more valuable than our own.
- Be mindful of your coworker's time
- Don't do half tasks and leave the rest to others
- Don't write code that will require others to fix
- If asking for help, provide all information in summarized form, without requiring your colleague to search for more details. Make sure this assistance session does not pass the 5 minute mark.
- If sharing information, provide it in full and concise form in a short text
- You're a noob? Don't ask veterans noob's questions.
Be an Owner, not a Renter
Revolutions aren't won by paid soldiers; they're won by true believers
in the cause, patriots.
A home owner treats his house better than a home renter.
Whereas renters are mercenaries, focused on short-term personal gain
not deeply vested into that the house (next year they will be renting
a different house), owners optimize for long-term outcomes,
bridge gaps in organizations, think and act beyond their job description.
They care deeply about their home - their workplace.
In Hola, we are all owners and not renters.
Introduced any new feature or application? Take full ownership of
it by adding yourself to the jdoc, and
by monitoring and influencing its progress.
We don't complain - we solve!
Complaints are words. Solutions are actions. Only actions make a change.
Take ownership of problems, don't hope someone else will solve them
for you.
Manager? Do it on your own first!
If you need to instruct the sales team how to sell the product, first sell it yourself. By doing a task first yourself you will know it better, and be able to give better instructions to others on how it should be done.
When to hire additional people to your team?
Hire additional person to your team for a specific function only once that
function is already working well in your team, and you just need one more
person to do it. This function should have already been proven to work well
by one of your existing team members.
Do not hire additional people to
your team if you are hoping that an additional person will bring new value
that your team is not yet bringing.
For example: You manage a marketing team, and you want to generate content
for press, but have never made a real 'machine' that can generate content and
get it published.
Do not hire a person to do this before proving it can
work with the existing team. Rather, one of the team members should create a
small machine that makes content (by writing it himself), getting interest
from publishers (by contacting them himself), and getting the piece
published. This experiment will teach the team if its at all possible to
create such a machine, what is needed to create such a machine, and what are
the exact requirements of the person to be hired.
On-call
Hola is a global company that provides mission-critical services for
countless customers and users. Therefore, we must ensure a very high level of
reliability. Each engineer shares responsibility for keeping our services
running smoothly 24/7/365.
Once you are familiar with the Hola infrastructure, you will join the on-call
rotation for your team. Each shift has a 2nd and 3rd line engineer, so there
is always help available if the problem is really serious.
We strive to make on-call incidents rare: once every few months, per
engineer. When possible, non-critical issues are handled in the next work
day.
Craftsmanship
Each of us strives to be the best in our field, and reach perfection,
make the smartest best possible decisions, and create the best products
possible.
Egolessness
Achieving a high level of craftsmanship requires complete egolessness;
focusing on the search for the 'truth', and understanding that our own ideas
might not always be the best ideas around. We should be open to accept
quickly any other, better idea, no matter who suggested it.
Great craftsmanship focuses on creating best results, not whether it was
our own idea.
Quality
We strive to produce great products. If we see a glitch, we don't just
refresh the browser's display and sit, self-content, to view the result - we
dig in to find what happened, even if the problem seems to have disappeared.
We try to re-create the problem, digging deeper until we find the root cause.
Problems don't just go away - they come back, more severe, at the worst
possible time. Finding and fixing problems early makes our products great.
Starting out at Hola, or in a new role at Hola
From a Google VP on starting off on the right foot in a new role:
"The advice I give to everybody coming in, is whatever your first project is,
no matter how much you hate it, spend your first six months executing
flawlessly on whatever you do. Don't pontificate. Don't go for the bigger
thing. Don't go for the grand, strategic objective. That stuff can wait six
months. Jump in with both feet. Respect the fact that your team has been
around forever and don't question everything. Figure out how they operate.
Treat them all with respect. Learn as much as you can and execute like crazy,
and that will buy you the option value to do whatever you want next.
Because, if people see you execute one thing, they'll think that you can
execute another thing, and another thing, and another good thing. There are
very few people who come in and do that truly professionally, but the people
who do end up setting themselves up super well."
Amazing Team
- The more top talent we have, the more we can accomplish.
- If the company is trying to solve the right set of problems, then it can create an environment that is challenging to top talent, and is able to provide these talents top of the market salaries and bonuses.
- We look for these top talents wherever they may be. We are not limited to geography, race, or religion. In fact, some of Hola's top contributing employees today are based outside of our main office in Israel.
-
We look for people that:
- Share much of our DNA, and are open to figuring it out and adopting it.
- Accomplish amazing amounts of important work
- Focus on great results that are important to Hola
- Exhibit bias to action over analysis
- Don't wait to be told what to do
- A great workplace can only be great if you are surrounded by stunning colleagues.
Effective and productive
Each of us chooses the tasks that bring the most value, and chooses the
most productive way to get them done
We measure the effectiveness of an action in whether it contributed to the
company's core - creating products that WOW our customers.
We measure our productivity in how fast and often we can be effective.
- Consider an employee who is proud of a report that he generated and distributed amongst 10 other employees. Was that effective? no! The product did not change - products are built from code, not spreadsheets, emails and presentations. It was even counter-productive: it wasted time of his 10 peers!
- Consider an employee who saw his relative use a Hola product with difficulty, created a quick mockup by drawing it on paper, estimating that it would take less than an hour to implement, so he quickly implemented it, and deployed it, and checked with his relative whether it made it easier to use. Was that effective? Definitely yes!
Work is only effective if it directly changed how we make a better product.
Productive
A good start to measuring our own productivity is whether we were able to complete tasks (big or small), deliver and deploy something every single day. Delivery and task completion are good signs for productivity.
Maximize impact
As technology workers, we have the opportunity to affect positive change at an unprecedented scale and rate. We have that opportunity because our individual work can impact millions of users within hours of being committed. At Hola we strive to make the most of that opportunity.
Bring value
Choose tasks that bring great value. Prioritize your tasks based on the
value they bring.
If you think you have a task that will not improve the customer value of
Hola's products, do not do this task.
Capabilities
If a task does not match your capabilities, and someone else can do it faster, try to have him take ownership.
Sane work hours
We do not believe in 'crazy startup work' - while the difference between
10 to 11 hours per day is 10%, the job burnout caused by working this extra
hour results in more than 10% ineffectiveness, and a single mistaken
decision will lead to 100% ineffectiveness.
This policy is based on our very personal experience: in Jungo and the first
year in Hola we believed that long work hours bring success.
After the first year in Hola, we decided we are completely different: No
working at night, no working on weekends, everybody needs to choose a
personally defined number of hours he feels comfortable with, a number that matches
his perception about the work-life balance required in order to enjoy life!
Don't work crazy hours at Hola, but during the hours that you do work, work
with 100% focus and dedication. Less hours, more focus.
We make HUGE efforts so that people do not have to work like in startup
world. We therefore expect that in the very very rare occasions where working
crazy hours is essential for solving an urgent customer problem, our
employees take up the challenge and put the necessary amount of work.
To summarize: We don't measure people by how many hours they work --
we do care about accomplishing great work.
Cost effective
When suggesting a change/improvement, look for the 'total overall cost'. For example, consider our DB has performance problems, and a developer may suggest to move to a different DB engine to solve the performance issues. When suggesting to move to a new DB, due to the suggested DB's 'pros', developers don't always take into account all its 'cons'. The old DB may have problems, but the new DB may also have a different set of its own issues. The old DB may also have features we rely on, which are unsupported by the new DB. At Hola, we always try to look at the big picture, and we prefer evolution where possible, instead of 'out with the old, in with the new'; namely, evolution instead of revolution. Back to the DB example, many times a small configuration change, patch, or schema change can solve performance issues, being a quick cost-effective solution to the problem.
Do not suggest to change things that have negative ROI
It's the responsibility of the developer who suggests the change to work out the 'total overall cost' of the change, and to validate that the suggestion has a large positive ROI, and that no simpler/quicker/cheaper/faster options can solve the issue at hand. We avoid implementing changes when the cost of the change is higher than the eventual positive outcome.
Short Simple Fast
Rule of thumb when evaluating any action/task/solution/code/document...:
Minimalism
We love extreme minimalism.
- We implement only what is really needed
- Work with tools only if they really help
- Ask questions only if we are really stuck
- Write code only if it solves a real problem
- Solve a problem only if it brings value
- Avoid over-engineering
This minimalism is deeply embedded in our daily work, and DNA:
- Email: Minimal recipients, Minimal signature, Avoid greetings, Single line emails where possible
- Code minimalism and condensity: removing every possible redundant token, spacing, comment, unless it's really needed. Choosing short concise names. Always favoring shorter code.
- Minimal Viable Product: implement minimal features to create a viable product.
- Meet only if needed
Email is a mission-critical tool for us - that's why we prepared
very detailed strict guidelines on how emails
should be written, sent, received, and handled.
Here are some highlights from our
Email guidelines:
- Eric Schmidt's 9 rules for emailing: Respond quickly, minimal words, clear inbox constantly, handle LIFO order, share if useful, don't BCC, BCC yourself for followup, forward yourself with search keywords.
- Minimal recipients
- Clear subject
- Avoid greetings
- Minimal signature
- Single line emails where possible
- Make discussions actionable
- Clarify action items
Summarize important discussions
When action items come up in a discussion with someone, or very important information is conveyed - immediately after the discussion send a summary email to that person (or make sure he sends to you), so that:
- you can make sure that you both understood it in the same way, and;
- so that you have reference for the future on what was agreed
The time it takes you to write this summary will allow you to consider which additional actions this requires, and who else needs to know about it.
Task organization
Don't trust your memory. Carry a pad and write things down. Systematically go over your list - you will see it's very satisfying to cross things off that list. At the end of a meeting or skype call, send a short summary email with action items.
"By example" design
We use specific examples rather than formal specification to define tasks and design features: mockups, wireframes, and textual examples.
Autonomous
We love working with people who can manage themselves and their tasks on
their own.
We find that a management style where micro-management is required,
guiding the individual contributor in many steps of the way and tracking
working hours and micro tasks kills our productivity and our
creativeness.
Thus, the perfect Hola'er is the person who finds his own tasks by
understanding his surroundings and deciding what would be of maximal value,
creating an MVP, sharing that with his supervisor and OK'ing the direction,
and then getting that done productively.
We find that this is more productive, and more enjoyable for all.
Responsible
Take responsibility and ownership for the problems and solve them on your own. Responsibility means that you are going ahead with a change and seeing it through, while understanding the risks and making sure that they are worth the outcome.
No need for others to fix
A great delivery is one that does not require anyone else to get involved in your tasks.
Check your work
No one will check your work - so do it well first time
You review your own code
We do not do code reviews (... except for new people, and they must very quickly do perfect commits, so we can stop doing their reviews).
Workflow: Write, Test, Review, Commit, Build, Deploy, Monitor
The flow of adding a feature/modification/bugfix is:
- Write: fully implemented change consists of
- code of the change itself
- unit tests
- deploy procedures
- zcounters and alerts for monitoring
- Test: emulate the product by using zlxc, and test your changes
- Review: do the following before commit:
- Run zlint on your code
- Run zmocha on your code
- Read full diff of your changes
- Hola Noobs Ask for a review from a peer
- Commit: concisely describe "what" and "why" in the commit message, and commit.
- Build: if BAT breaks - revert
your change or fix it immediately.
You already wrote the unit-tests for BAT during the Write phase. - Deploy: get your code to the field ASAP
You have already updated procedures for the deploy team during the Write phase. - Monitor: keep an eye on a monitoring system.
You have already added zcounters and alerts during the Write phase.
Never 'lose' emails, tasks & AIs
We are each totally responsible for our own tasks, nobody will follow us
up.
So we can't let tasks get 'lost'. We don't 'forget' things.
How? With tools:
- Manage your inbox: this prevents emails from getting lost - minimal inbox, and archiving/deleting emails only when handling.
- Use version_plan & calendar for long term AIs: these are 'long term' memory tools, so that tasks are never forgotten.
- Pen & paper in customer meetings: always having a pen & paper whenever meeting a customer on skype, video call or face to face, will prevent forgetting meeting AIs. Do this also when you come to get feedback or advice from a peer inside the company - you are taking up your peer's time for your own personal task, so don't miss any of the things you learned just because you didn't write them down. Transfer AIs you don't immediately implement to your 'long term memory' tools (version plan, calendar...).
Trust judgement over rules
Rather than rely on hard rules that dictate behavior, we give ourselves the flexibility to apply judgment at the time a decision is being made. This allows us to incorporate more context about what is happening, enabled by the trust we share in the decision-making abilities of our teammates.
Truthful
Communicate, look at problems and evaluate ourselves truthfully
We seek truth: What does the user really want? What is the
best way to solve a problem? How can we make our customers happy?
When facing these questions, we put workplace politics and
personal egos
aside, and focus on the search for the best, most truthful, and
correct answers.
We believe that seeking the real truth will contribute to make better
products and a better workplace.
Pride in mistakes
Everyone makes mistakes, especially
people who get a lot done.
Therefore, we're constantly on the look for our own mistakes. Once we detect
and fix them, we are on a better trajectory, personally and as a group.
Finding our own mistakes is an "AHA!" moment. We take pride in it, and we
share it - along with the new conclusion - with our peers, since some of them
are probably in the same, wrong mindset in which we were before.
We learn the most from the mistakes we make: Let's share them so that we
don't make them again, but rather improve as a group. We can share our own
mistakes by sending a case study to all that are relevant. If you make a
mistake, don't try to hide it. On the contrary, understand what happened, fix the
mistake, as well as the flaws in the system that made the mistake possible.
Mistakes are a great learning opportunity that allows for improvement.
Correcting mistakes
Making mistakes is part of the culture of running fast, and we all make
them.
If our goal was to be 100% mistake-free, we would be slowing our progress
at Hola to a halt.
Imagine a waiter who has to make sure 100% that he never breaks any dishes
he carries.
He will carry less dishes, and walk very slowly - not very productive!
If he were to be only 99% break-free,
breaking a dish once in a while, he would be 10x more productive: carrying
more dishes, and walking much faster.
We prefer to be of the second sort.
When identifying that a mistake has been made we need to apply some deep
thinking to figure out other areas that this mistake may have affected.
Back to the waiter example, once a glass breaks you need to consider what
the consequences are - where may have the glass shreds ended up,
do you need to put in an order for a new glass,
are there other repercussions?
An example from our work; a Biz Dev (BD) person signs up a new customer,
and in the internal email misspells the name of the customer.
Not a problem, but requires some thinking now - what are the actions that
need to be done? Send a corrective email, go to finance department and ensure
that the customer was not entered in the financial systems incorrectly
(to avoid mismatches down the road), go to IT to make sure that the
customer was not activated under the wrong name, etc.
The next step after correcting the immediate results is finding how to
improve the overall system, to prevent these mistakes from happening again.
In the waiter example, after a few dishes dropped he offered to have a
rubber mat on the tray to avoid much of the jiggle, resulting in
less broken dishes and even faster possible walking speeds.
"5 Solutions": Solve problems in 5 ways
Every problem or mistake that we investigate is a side effect of a bigger,
deeper problem.
We avoid solving problems in advance, but once
a problem does happen, we make sure to thoroughly solve it in 5 different
ways, with 5 different solutions, thereby preventing the future occurrence of
not only this specific type of problem, but also of many other, related
problems.
This is originally based on Toyota's
Ask "Why?" 5 times,
but adapted to our action-oriented DNA of
'solving' rather than 'complaining'.
We have in place many systems and procedures to prevent mistakes and to
catch them once they happen - all built as solutions for past mistakes. If a
bug/mistake slipped through all traps, the purpose of the '5 Solutions'
is to create new mechanisms and work methods that will prevent the future
occurrence of such bugs.
Most 'solutions' we implement are 'traps' that help us
trap/catch/prevent the bug/problem/mistake:
- linter: will trap bugs even before you first run the code
- unittest: will trap bugs before commit, or in the BAT
- test procedures: will trap problems before release, in the deploy stage
- zcounters: will trap after deploy, but will minimize the impact, by alerting - thus it will quickly be reverted.
- procedures: modifying a procedure in a way that will better trap new
kind of mistakes. Such as the developer
workflow procedure that we
modify constantly to help trap more and more different kinds of common
mistakes.
The email procedure was also written as a result of mistakes in email handling - thus helping the rest of the team avoid those mistakes.
5 sounds too many?
Too hard to find many ways to address the same problem?
The number 5 is not a strict rule. The quality of doing 5-Solutions
is by the quality of the solutions and action items, not the number.
Even if you only have 2 solutions for the incident, but the solutions
suggested and implemented give great value for the company - then 2
solutions is enough!
Here are questions that will help you find more root causes, and
thus more possible solutions:
- Why didn't the current procedures/work methods/tools prevent this problem?
- What procedure/tool should I modify to prevent this in the future?
- Do others also make this kind of mistake?
- How can I help my peers avoid it?
- Even if one trap didn't catch this mistake, what additional traps could I add that would have caught it from a different direction?
- Even if all traps didn't catch this bug, what post-release monitor/alerting trap can I add to detect the bug in the field, enabling early detection and minimizing the bug's impact?
- Why did this happen again? Why wasn't the previous fix thorough enough?
- Why do my peers tend to repeat doing this mistake?
- How can I teach my peers how to avoid this kind of mistake?
- Why did people not follow the existing procedures that prevent this mistake from happening?
- How to make it easier for others to avoid such mistakes?
- What tools are missing that would help find/solve/prevent this?
Initiate '5 Solutions' process
Problems and mistakes can happen in your domain, for which you have to
execute a '5 solutions' process, immediately once found, to resolve them.
It is also quite often that a veteran, who was
an eyewitness to a problem or mistake in your domain, will ask you to
consider initiating such a process. In such a case, our Hola way of thinking
is also investigate ourselves by asking 'How come I did not see it before?'
'5 Solutions' time line
Once initiating a '5 Solution' process, it should end in a timely manner, so
such a problem or mistake will not reoccur.
Your actions should be fast:
- Invest 10 minutes to understand what happened and provide an initial feedback to all concerns. Then,
- Invest 1-2 hours to deeply understand the problem, provide a solution and report to all concerns about your findings, solution and execution
'5 Solutions' example
'cdn bytes' metric did not notify a critical problem - here is a '5 Solutions' process description:
This thorough handling of a problem will not only fix the specific problem that occurred, but will also prevent/fix many related future problems of various types.
Answering 'why?'
Sometimes you will be asked to explain why did you take a certain action.
Such a process of answering 'why?' give us an opportunity to either enhance
our procedures, in case it was good idea, or fix completely an identified
problem, in case it was a mistake.
In case a mistake was identified, you wil be asked not only to fix this
specific one but also taking all required actions preventing others from
doing the same mistake again (e.g. executing
5 solutions report).
Check our email conventions to see how to
answer a why email.
Clean up yourself
Sometimes our peers discover our mistakes. In such cases we should be thankful for the time and effort they spent on finding mistakes. As part of good peer relationship, and honoring our peer's time, we try to acknowledge the mistake as quickly as possible and "clean up the mess" ourselves - releasing our peer from any further involvement:
- We immediately email: "Thanks. FIXED" if possible to fix immediately, or "Thanks. Will be fixed by tomorrow" if the fix takes time
-
We think whether this mistake might have been repeated by us or others
in the codebase, and we rgrep and fix
all mistakes of the same class as this one.
In our email back to our peer we will add
"I rgrep'ed and found mistakes of this type made by me in 5 other places,
plus 20 more mistakes of this type made by others, and I FIXED them all".
This will put your peer's mind at rest that you made a thorough fix, not a shallow one, thus preventing him from having to send you an email such as "OK - you fixed this specific bug occurrence, but did you check the whole codebase for additional appearances of such a bug?" - Once the fix is deployed, send another email updating your peer that the fix is live, so that he now has a chance to see if the fix puts his mind at rest.
- Prepare by yourself, on your own initiative, a 5 solutions report. This gives your peer additional confidence that you carried out an extensive fix of the root cause of the mistake he found, and keeps his mind at rest.
It's very common that when someone points out a mistake, the receiver tries to explain why the mistake was done, why it's not such a big mistake, that such things happen and so on. However, at Hola we thrive on running fast and recognize that mistakes happen, so responses of this type become irrelevant and a sheer waste of time. We acknowledge making a mistake, thank him for finding it, fix the mistake and move on to the next big thing!
'bad news'? Learn from it!
There is no 'bad news'. News makes us learn.
Consider that if we've done good so far, and now we know something
that we're not doing well (such as a bug, or a mistake in our strategy),
then once we fix that problem we are on an even better path.
Don't categorize news into 'good news' and 'bad news'.
It's all good news, because we learn from it.
For example; a customer tells us he is switching from Hola to a competitor.
Is that bad news? No "this is a great opportunity to learn about where our
service is not good enough for this customer and to improve it.
Consider that after this our service will be better"
we will retain more customers, and sign up new customers at a faster pace!
If we hid this important information, for example by saying
(for guys not in sales, this is a common excuse...), then we are losing important information that could allow us to learn and improve!
Trustworthiness
Every company says that trustworthiness is key in its employees.
But why is it important to us?
Our basic premise is that we each work independently on our tasks,
with P2P communications between us.
There is no manager looking over the shoulder (and if there is, then
something is not working right).
Therefore, we have complete trust in all of us to be doing what's right
for the company, for carrying the company's DNA into whatever task we
have (remember that our success is a byproduct of our DNA),
and for identifying mistakes and issues and fixing them at a DNA level.
Let's take that example of the salesperson who lost a customer.
If that salesperson is untrustworthy and wants to look good by stating
that he lost the customer due to "Internal customer politics",
then he sets the whole company back by hiding important information,
thereby preventing us from producing the best possible product.
Let's also take a look at what will happen when another person from Hola
revisits that customer and finds out the real reason why the customer left
us. It will reflect on our communication, which from that point will be more
cautious and less trusting. This is intolerable from a DNA perspective.
There are second level aspects of trustworthiness and truthfulness that are
not as apparent: read about them in the next sections on Debating and mind
change.
Debating
It's human nature to try to convince that your position is the right one.
However, in a productive environment you need to ensure that you are
not 'overselling' your solution and in the process are 'hiding' some of its
pitfalls and some of the merits of the alternative.
In our environment, presenting a view that is not neutral (for example, by not
showing the real downsides of your proposed solution) will typically
not convince your peers of your solution.
It's more important you focus on the cons of your own suggestions and
the pros of your peer's suggestions, to make your suggestion more credible:
A good scientific theory is one that suggests an experiment to
disprove the theory.
At Hola, finding out the true reason for something, and fixing it,
will result in success as a "side effect".
Therefore, when debating an issue, show the arguments for both sides,
as well as your conclusion.
Your peer in the debate may show more arguments for the other side and
eventually cause you to tilt back to the other position.
Tilt to that other position with pride!
Proud of changing our mind
If the sky is not blue - I desire to believe that the sky is not blue.
What seemed correct yesterday may not seem correct today. We commit to tracking the truth, changing as new data becomes available. This way progress is not stifled by yesterday's 'truth'. We try to have a strong opinion, but are always ready to switch it fast when we have new data, taking pride in changing our mind.
In a super-fast work environment, we learn new things frequently, and must therefore adapt our opinions accordingly, fully aware that evolution brings success.
Choose to bring value to our customers
There are various ways for a company to succeed, for example: by doing great
marketing for mediocre products.
We choose to succeed by creating products that bring great value to our
customers (typically through technological disruptions). When considering
our roadmap, we choose to do things that make our products bring higher value
to the customer, rather than things that bring us shorter-term profit. Why?
Because that's how we can succeed over the long term - by having products that
are difficult to compete with, and customers who trust us. We are marathon
runners, not sprinters.
Discussions around product features should be about the value they bring to
the customer, not the value they bring to Hola.